reverse intro
02/05/2018hexadecimal
Le système hexadecimal utilise une base 16. C’est à dire que chaque caractère peut prendre 16 valeurs différentes.
| base 10 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| base 16 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f |
On préfixe les nombres hexadécimals souvent par un Ox afin de les différencier des autres bases.
| base 10 | 8 | 20 | 29 | 32 | 74 | 90 | 100 | 999 | 1000 |
| base 16 | 0x8 |
0x14 |
0x1d |
0x20 |
0x4a |
0x5a |
0x64 |
0x3e7 |
0x3e8 |
base 10 to base 16
| …. | 163 | 162 | 161 | 160 |
|---|---|---|---|---|
| …. | 4096 | 256 | 16 | 1 |
| …. | 0 | 3 | 14 | 7 |
(999)10 = 3 * 256 + 14 * 16 + 7 * 1
(999)10 = 3 * 162 + 14 * 161 + 7 * 160
(999)10 = 3 * 162 + E * 161 + 7 * 160
(999)10 = (0x3E7)16
memory space
Combien de bits pour coder un caractère en base 16 ?
Chaque caractére peut prendre 16 valeurs :
- 1 bit -> 21 = 2 combinaisons
- 2 bits -> 22 = 4 combinaisons
- 3 bits -> 23 = 8 combinaisons
-
4 bits -> 24 = 16 combinaisons <– Donc 1 caractère occupe 4 bits.
0x8-> occupe 4 bits0x4A-> occupe 8 bits -> 1 octet0x4A88-> occupe 16 bits -> 2 octets
memory addressing
On utilise souvent la base hexadécimale pour donner des adresses mémoires. Par exemple 0x000008ff est une adresse mémoire sur une machine 32 bits.
Les machines 32 bits ont 32 bits d’adressage (ou 4 octets), c’est à dire que l’on peut localiser 232 blocs de 1 octet dans la RAM. C’est à dire 4 Go maximum.
Les processeurs 64 bits quand à eux peuvent adresser 264 blocs différents. C’est à dire BEAUCOUP !
assembler (asm)
Voici un exemple de code écrit en langage C :
/* main.cpp */
int main (int arc, char* argv[]) {
int nb1 = 10;
int nb2 = 100;
if(nb1 > nb2) {
printf("%i est plus grand que %i", nb1, nb2);
} else {
printf("%i est plus petit que %i", nb1, nb2);
}
return 0;
}
Le processeur d’un ordinateur ne peut réaliser que de simples opérations (additions, soustractions, comparaison à 0,…). Il ne peut donc pas directement interpréter notre main.cpp. C’est pour cela que l’on passe par une phase de compilation qui nous permet d’obtenir un exécutable compréhensible par notre processeur.
example
0x000008d6 83f80a cmp eax, 0xa
0x000008d9 7513 jne 0x8ee
0x000008db 488d3d430100. lea rdi, qword str.Gagne
0x000008e2 b800000000 mov eax, 0
0x000008e7 e834feffff call sym.imp.printf
0x000008ec eb11 jmp 0x8ff
0x000008ee 488d3d440100. lea rdi, qword str.Perdu
0x000008f5 b800000000 mov eax, 0
0x000008fa e821feffff call sym.imp.printf
0x000008ff b800000000 mov eax, 0
0x00000904 c9 leave
0x00000905 c3 ret
La colonne de gauche représente les adresses mémoires (on reconnait la base hexadécimale 0x...), la seconde est le contenu mémoire (données stockées) jusqu’à la prochaine adresse mémoire. Enfin, la troisième colonne est la traduction de ce contenu en langage assembleur. Par exemple, eb11 est traduit par l’instruction jmp 0x8ff.
addresses evolution
Prenons par exemple les 4 premières lignes
| adresse (hexa) | contenu (hexa) | directive (assembleur) |
|---|---|---|
0x000008d6 |
83f80a | cmp eax, 0xa |
0x000008d9 |
7513 | jne 0x8ee |
0x000008db |
488d3d430100 | lea rdi, qword str.Gagne |
0x000008e2 |
b800000000 | mov eax, 0 |
Rappel
- un caractère hexadécimal occupe
4 bits - un case memoire fait 1 octet
Pourquoi passe t-on de l’adresse 0x000008d6 à 0x000008d9 ?
Tout d’abord l’adresse 0x000008d6 pointe sur une suite de données correspondant à la directive 83f80a. Cette directive est une valeur hexadécimale qu’il faut stocker. Etant donné que 83f80a est composée de 6 caractéres hexa, il faut donc 3 octets pour stocker cette directive (6*4 = 24 bits = 3 octets).
De plus si on regarde le delta de 0x000008d9 - 0x000008d6 on retouve la valeur 3. Tout s’explique.
Voiçi un tableau avec le contenu de chaque case mémoire :
| adresse (hexa) | directive (hexa) |
|---|---|
0x000008d6 |
83 |
0x000008d7 |
f8 |
0x000008d8 |
0a |
0x000008d9 |
75 |
0x000008da |
13 |
registers
Important: plus on est proche du processeur, plus la mémoire est rapide, plus vite sont exécutées les instructions.
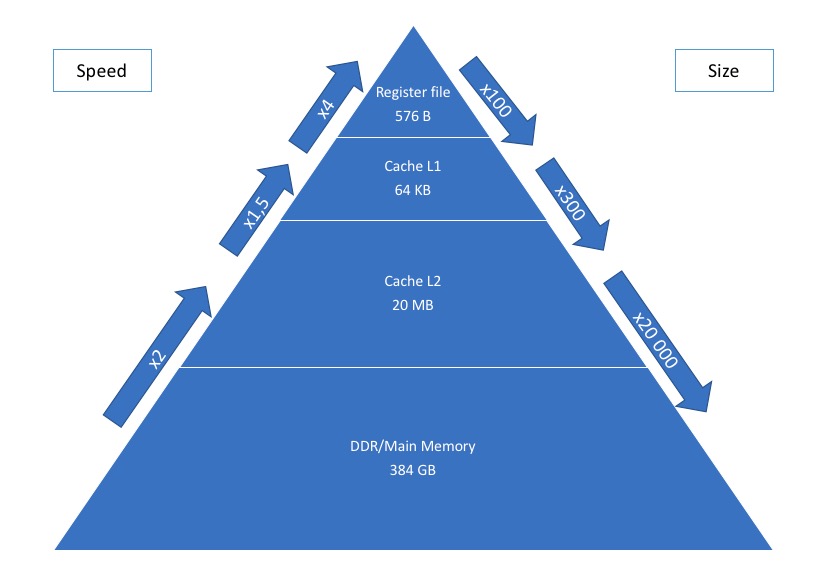
Les registres forment une mémoire interne aux processeurs, plus on a de registres, plus on peut stocker de données, et moins on a besoin d’accès aux mémoires extérieurs (qui sont bien plus lentes).
Les processeurs x86 en 32 bits possèdent 8 registres généraux (EAX, EBX, ECX, EDX, ESP, EBP, ESI, EDI). En 64 bits, on passe à 16 registres logiques, mais dans les faits, il en existe bien plus (ex: 168) afin de paralléliser les instructions.
data registers
Ils sont utilisés pour stocker des résultats d’opérations élémentaires lors de l’exécution du programme.
| registre | définition | utilisation |
|---|---|---|
AX |
Accumulator Register | opérations input/output, et opérations arithmétiques |
BX |
Base Register | pour indexer des adresses |
CX |
Counter Register | index dans les boucles itératives |
DX |
Data Register | opérations input/output |
De ces 4 registres, il existe plusieurs dérivés.
| 64-bits | 32-bits (p. faible) | 16-bits (p. faible) |
|---|---|---|
RAX |
EAX |
AX |
RBX |
EBX |
BX |
RCX |
ECX |
CX |
RDX |
EDX |
DX |
R: register
E: extended
H: high
L: low
Il existe aussi des registes de 8 bits pour A, B, C et D. Il suffit de rajouter H pour avoir les bits de poids fort, et L pour les bits de poids faible.
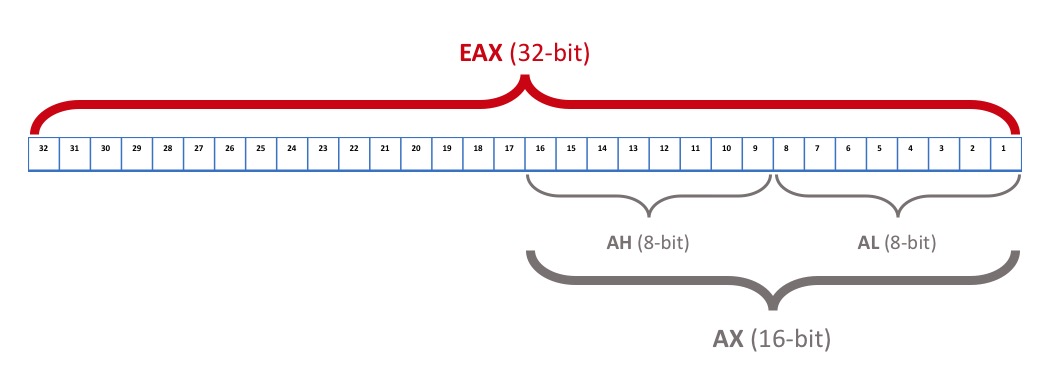
Cette variété de tailles de registres permet de stocker des données selon la taille qu’elles nécessitent.
pointer registers
Ils sont utilisés pour pointer des adresses mémoires.
| registre | définition | utilisation |
|---|---|---|
SP |
Stack Pointer | adresse libre de la stack (pile) (offset) |
IP |
Instruction Pointer | prochaine adresse de l’instruction à exécuter (offset) |
BP |
Base Pointer | reférence les paramètres d’une routine |
PC= IP = Instruction Pointer (en x86)
ESP et EBP stockent des adresses 32 bits pour délimiter le stack frame courante.
À partir de ces 3 registres, il existe plusieurs dérivées.
| 64-bits | 32-bits (p. faible) | 16-bits (p. faible) |
|---|---|---|
RSP |
ESP |
SP |
RIP |
EIP |
IP |
RBP |
EBP |
BP |
index registers
| registre | définition | utilisation |
|---|---|---|
SI |
Source Index | index source pour opérat. sur les chaines |
DI |
Destination Index | index de destination pour opérat. sur les chaines |
À partir de ces 2 registres, il existe plusieurs dérivées :
| 64-bits | 32-bits (p. faible) | 16-bits (p. faible) |
|---|---|---|
RSI |
ESI |
SI |
RDI |
EDI |
DI |
control registers (flags)
Ces flags de 16 bit sont mis à jour après chaque opération.
| 64-bits | 32-bits | 16-bits |
|---|---|---|
RFLAGS |
EFLAGS |
FLAGS |
Par exemple, EFLAGS contient des indicateurs, des interrupteurs, etc… Ces flags sont essentiellement utilisés pour des comparaisons, mais pas que.
| registre | définition | utilisation |
|---|---|---|
OF |
Overflow Flag | si dépassement de capacité d’une donnée après une opération |
DF |
Direction Flag | |
IF |
Interrupt Flag | l’exécution doit-elle être à l’écoute des évenements extérieurs (clavier, souris) |
TF |
Trap Flag | on dit au processeur qu’on peut exeuctuer le programme pas à pas (instruction par instruction) (mode debug) |
SF |
Sign Flag | signe d’une opération |
ZF |
Zero Flag | |
DF |
Direction Flag | resultat d’une opération qui fait 0 |
AF |
Auxiliary Carry Flag | |
PF |
Parity Flag | bit de parité |
CF |
Carry Flag |
Il en existe d’autres…
segment registers
Pour décrire le partage mémoire.
Utilisé pour faciliter la lecture et l’écriture sur la mémoire.
| registre | définition | utilisation |
|---|---|---|
CS |
Code Segment | adresse de début des instructions |
DS |
Data Segment | adresse de début des données |
SS |
Stack Segment | adresse de début de la stack (pile) |
Il en existe d’autres qui ont le rôle de définir d’autres espaces mémoires comme ES, FS, GS.
adressage
Toute adresse dans une programme est définie par l’adresse de début de segement et par le décallage (offset). Cela nous permet de trouver l’adresse exacte d’une instruction grace à la somme de ces 2 valeurs.
initialized variables
[nom_variable] taille valeur
| taille | définition | nombre d’octets aloués |
|---|---|---|
DB |
Define Byte | 1 |
DW |
Define Word | 2 |
DL |
Define Doubleword | 4 |
DQ |
Define Quadword | 8 |
# exemple de définition de variables
ma_lettre DB 'm'
mon_age DW 12345
mon_negatif DW -12345
grand_nombre DQ 123456789
reel DD 1.234
unitialized variables
| taille | définition | nombre d’octets reservé |
|---|---|---|
RESB |
Reserve Byte | 1 |
RESW |
Reserve Word | 2 |
RESD |
Reserve Doubleword | 4 |
RESQ |
Reserve Quadword | 8 |
REST |
Reserve Ten Bytes | 10 |
constantes
CONSTANT_NAME EQU expression
TOTAL_STUDENTS equ 50
# numeric constant
%assign TOTAL 10
# both numeric and string constants
%define PTR [EBP+4]
unary operations
- DIV divisor ; unsigned data
- IDIV divisor ; signed data
- 16-bit: (AX) / 8-bit divisor = AL(quotient) and AH(remainder)
- 32-bit: (DX AX) / 16-bit divisor = AX(quotient) and DX(remainder)
- 64-bit: (EDX EAX) / 32-bit divisor = EAX(quotient) and EDX(remainder)
idivq S->RDX:RAX/S= RAX(quotient) and RDX(remainder)divq S->RDX:RAX/S= RAX(quotient) and RDX(remainder)
| instruction | description |
|---|---|
inc D |
D = D + 1 |
dec D |
D = D - 1 |
neg D |
D = -D |
not D |
D = non D |
binary operations
| instruction | description |
|---|---|
leaq S, D |
D = S |
add S, D |
D = D + S |
sub S, D |
D = D - S |
imul S, D |
D = D - S |
xor S, D |
OU exclusif |
or S, D |
OU logique |
and S, D |
ET logique |
| instruction | définition |
|---|---|
MUL multiplier |
D = D + 1 |
IMUL multiplier |
D = D + 1 |
MUL multiply unsigned data
IMUL integer mutltiply signed data
AL*multiplier(of 8-bit) =AH AL=AXAX*multiplier(of 16-bit) =DX AXEAX*multiplier(of 32-bit) =EDX EAXimulq S->RAX*S(of 32-bit) =RDX:RAXmulq S->RAX*S(of 32-bit) =RDX:RAX
logic instructions
conditions
# compare desti à src avec soustraction
CMP desti, src
CMP DX, 00
JE L7
...
L7: ...
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1
# faire un saut sur un label
JMP label
| instruction | description |
|---|---|
cmp S2, S1 |
set condition codes to S1-S2 |
test S2, S1 |
set condition codes to S1 & S2 |
| jump | définition | flags touchés |
|---|---|---|
jump Label |
jump to label | |
jump Addr |
jump to address | |
je/jz Label |
jump equal/zero | ZF |
jne/jnz Label |
jump not equal/nonzero | ZF |
js Label |
jump if negative | SF |
jns Label |
jump if nonnegative | SF |
jg/jnle Label |
jump if greater | OF, SF, ZF |
jge/jnl Label |
jump if greater or Equal | OF, SF |
jl/jnge Label |
jump if less | OF, SF |
jle/jng Label |
jump if less or equal | OF, SF, ZF |
data movement
Instruction with one suffix
| instruction | description |
|---|---|
mov S, D |
move source to destination |
push S |
push source onto stack |
pop D |
pop to of stack into destination |
Instruction wih two suffix
| instruction | description |
|---|---|
mov S, D |
move source to destination |
push S |
push source onto stack |
Instructions with no suffixes
| instruction | description |
|---|---|
cwtl |
convert word in %ax to doubleword in %aex |
cttq |
convert doubleword in %eax to quadword in %rax |
cqto |
convert quadword in %rax to octoword in %rdx:%rax |
virtual memory
Lorsque l’on lance un programme, celui-ci est chargé en mémoire afin d’être exécuté. Pour cela, un processus est créé. Ce processus ne possède pas d’accès direct à la mémoire physique de la machine. Mais il va avoir accès à une mémoire virtuelle d’une taille de 4 Go (sur machine 32 bits). Le processus est encapsulé dans une sandbox (bac à sable) afin d’être séparé des autres. Lors de son exécution, le processus pense être seul à s’exécuter sur la machine (ce qui n’est pas le cas).
page tables
Les tables de pages sont utilisées pour créer une interface entre la mémoire virtuelle (point de vue du processus) et la mémoire physique (point de vue machine). Chaque processus est associé à une table de page. Cette table associe les espaces mémoires virtuelles utilisés par le processus, avec des espaces physiques de la mémoire. C’est le kernel qui réalise cette tâche.
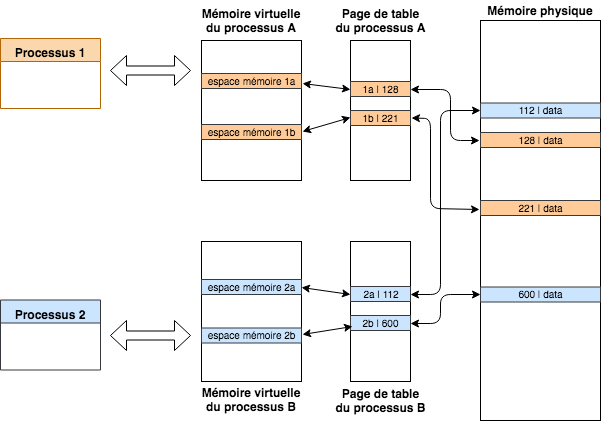
On peut voir sur ce schéma que le processus 1 a accès à une mémoire virtuelle. Derrière celle-ci se cache le système de table de page vue précédemment.
memory segmentation
Lorsqu’un programme est chargé en mémoire afin de créer un processus la mémoire est segmentée.
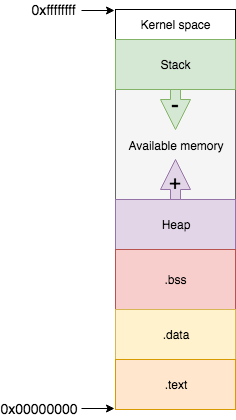
| Section | Déscription | Taille |
|---|---|---|
.text |
instructions du prog., read-only, là que commence le programme | fixe |
.data |
var. globales et statiques initialisées | fixe |
.bss |
var. globales et statiques non initialisées | fixe |
$ size ./rop # taille des sections + ajouter code
| Zone mémoire | Déscription | Adresses | Taille |
|---|---|---|---|
stack |
var. locales des fonctions, cadre de pile (stack frame) | croissantes | variable |
heap |
pour allocation dynamique du programmeur (malloc, calloc) | décroissantes | variable |
stack frame : zone mémoire dans la pile, avec toutes les informations nécessaires à l’appel de cette fonction + var. locales de la fonction.
example
On peut utiliser la commande size afin de connaitre la taille des séctions.
// main.c
#include <stdio.h>
int main (int argc, char* argv[]) {
return 0;
}
$ gcc main.c -o a.out
$ size a.out
text data bss dec hex filename
1537 544 8 2089 829 a.out
On peut voire la taille des séctions de notre exécutable de départ.
// main.c
#include <stdio.h>
int var_global;
int main (int argc, char* argv[]) {
// ou static int var_static;
return 0;
}
$ gcc main.c -o a.out
$ size a.out
text data bss dec hex filename
1537 544 12 2089 829 a.out
La variable var_global est non initialisée, elle se retrouve donc dans la section .bss. Même chose si nous avions définie une varaible static dans le main().
// main.c
#include <stdio.h>
int var_global_1 = 10;
int main (int argc, char* argv[]) {
return 0;
}
$ gcc main.c -o a.out
$ size a.out
text data bss dec hex filename
1537 548 8 2089 829 a.out
La variable var_global est maintenant initialisée, elle se retrouve donc dans la section .data.